How do we use chatgpt 3.5-turbo to controll virtual agents?
Connecting the ChatGPT API
Get Your API Key
Sign Up: First, sign up for an account at OpenAI.
API Key: Once registered, navigate to the API dashboard to create and retrieve your API key. This key is used to authenticate your API requests.
Install the OpenAI Client Library
pip install openai
Making First API Call
from openai import OpenAI
client = OpenAI(api_key="Your Key")
# Create a chat completion request
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "How do I use the ChatGPT API?"}
],
temperature=0.7
)
print(response.choices[0].message.content)
Using the GPT API to influence decision-making in robotics or simulated environments
High-Level Control vs. Real-Time Execution
- High-Level Decision Making:
The GPT API is designed for generating natural language responses based on textual prompts. It can be used to provide high-level instructions or planning, which could then be translated into low-level control commands. For example, you might use it to generate strategies or action sequences in a robotics task.
- Real-Time Control Limitations:
Robotics control often requires precise, real-time responses with low latency, something that the GPT API isn’t optimized for. The API introduces network latency and is generally slower compared to the control loops typical in robotics. Thus, it might be more suitable for non-time-critical, high-level decision making rather than direct, real-time motor control.
Example of CartPole environment
The CartPole environment is a classic benchmark in reinforcement learning and control theory. It simulates a simple yet challenging problem: balancing a pole on a cart.
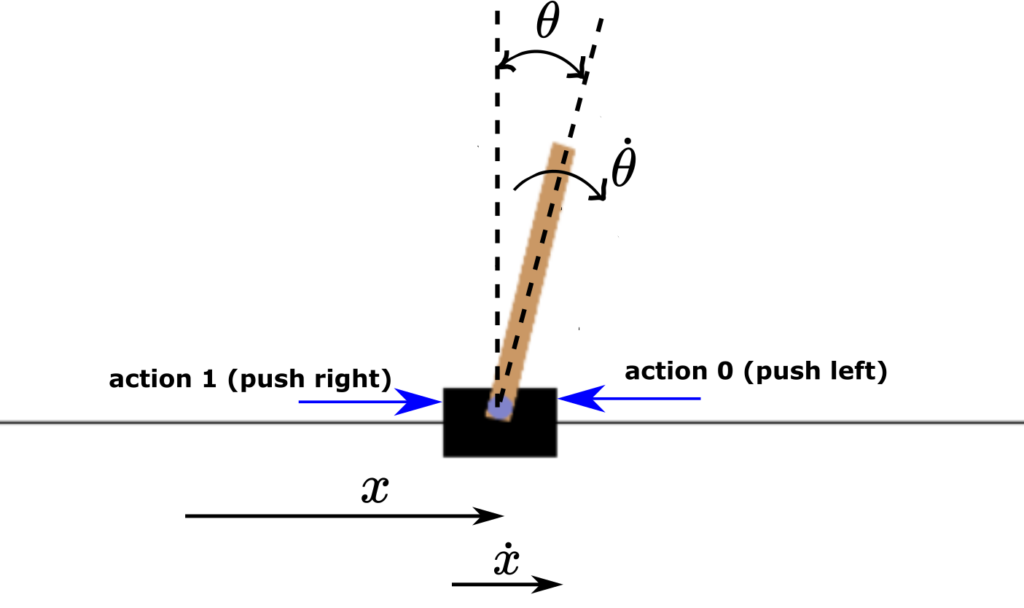
Setup:
A pole is attached to a cart via a hinge, and the cart can move left or right along a track.
State Variables:
- Cart’s Position: The location of the cart on the track.
- Cart’s Velocity: The speed at which the cart is moving.
- Pole’s Angle: The angle of the pole relative to the vertical.
- Pole’s Angular Velocity: The rate at which the pole’s angle is changing.
Actions:
Typically, the agent can take one of two actions:
- Apply a force to move the cart left
- Apply a force to move the cart right
Objective:
The goal is to keep the pole balanced upright for as long as possible. The agent usually receives a reward (often +1) for each time step that the pole remains balanced.
Dynamics:
The environment is challenging due to its unstable dynamics. Even a small deviation in the pole’s angle can lead to a fall, requiring quick and accurate adjustments by the agent.
You can then integrate the GPT API with a Gym environment by setting up an interface that translates the environment’s state into a textual prompt and then interprets the model’s output as an action.
State Representation: Convert the current state (observations) of your Gym environment into a text description.
Generate Action Command: Use the GPT API to generate a recommended action based on the provided state.
Interpret and Execute: Parse the output from the GPT API to determine which action to take, then pass that action to the Gym environment.
Iterate: Repeat the process, updating the prompt with the new state after each action.
Here is the
from openai import OpenAI
import gym
import time
import re
# Set your OpenAI API key
client = OpenAI(api_key="Your_Key")
if __name__ == '__main__':
# Create the CartPole environment with human render mode to display a window
env = gym.make("CartPole-v1", render_mode="human")
observation, info = env.reset()
done = False
while not done:
# Construct a text prompt from the current state of the environment
prompt = (
f"Current CartPole state: {observation}\n"
"Based on this state, choose the optimal action to balance the pole.\n"
"Available actions: 0 (move left) or 1 (move right).\n"
"Return exactly one number (0 or 1) with no additional text."
)
# Start timing before the GPT API call
decision_start = time.perf_counter()
# Call the GPT API to get a recommended action
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}],
temperature=0.2 # Lower temperature for more deterministic output
)
# End timing after the API call completes
decision_end = time.perf_counter()
decision_time = decision_end - decision_start
print(f"Decision making took: {decision_time:.3f} seconds")
try:
# Extract and parse the action from the GPT response
action_str = response.choices[0].message.content.strip()
# Use regex to extract a valid action (0 or 1)
match = re.search(r"\b(0|1)\b", action_str)
if match:
action = int(match.group(0))
else:
print(f"Couldn't extract a valid action from GPT output: '{action_str}'. Defaulting to 0.")
action = 0
except Exception as e:
print("Error parsing action, defaulting to 0:", e)
action = 0
# Execute the chosen action in the environment
observation, reward, done, truncated, info = env.step(action)
print("Observation:", observation, "Reward:", reward, "Done:", done, "Truncated:", truncated, "Info:", info)
# Render the environment (this should update the window)
env.render()
# Optional: slow down the loop for visualization purposes
time.sleep(0.01)
# Reset the environment if the episode is done
if done or truncated:
observation, info = env.reset()
Result
Below is the experiment using the CartPole environment under two different policies—one using GPT-based decision making and the other selecting random actions. The script runs a few episodes with each method, collects total rewards and average decision-making times per step, and finally plots a bar chart comparing both policies.
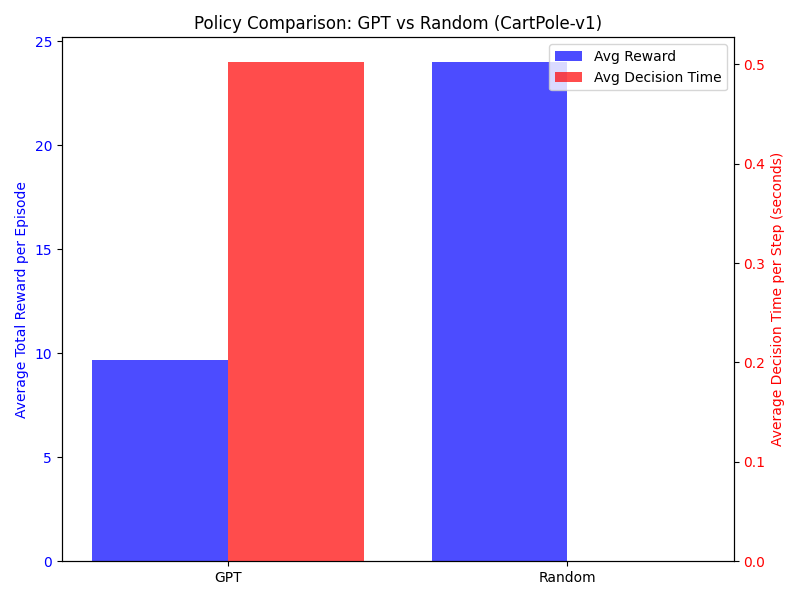
As illustrated in the figure, using ChatGPT 3.5-turbo for control tasks is slower and often yield worse performance than a random policy.
Conclusion
In this work, we explored using the ChatGPT API to control a virtual agent in a simulated environment, specifically the CartPole-v1 gym environment. We demonstrated how to convert the environment’s state into a text prompt, use ChatGPT to generate an action recommendation, and interpret the output to drive the simulation. Our experiments compared the GPT-driven policy to a random policy, revealing that ChatGPT 3.5-turbo is considerably slower and often less effective.
There are a few key reasons why using ChatGPT for control tasks can be slower and often yield worse performance than a random policy:
Network Latency and Overhead:ChatGPT requires a network call for every decision, which introduces significant latency compared to a local, instantaneous random action selection.
Not Designed for Real-Time Control: ChatGPT is optimized for natural language generation rather than real-time decision making. It lacks the fine-tuned control strategies that are developed by dedicated reinforcement learning or control algorithms.
Suboptimal Prompts and Interpretation:The textual prompts may not capture all the nuances of the environment state, and ChatGPT might not reliably generate the optimal control action. In contrast, a random policy, while not intelligent, acts immediately without the complexities of language interpretation.
Complexity Mismatch: Virtual control tasks like balancing the CartPole require quick, precise responses. ChatGPT’s high-level, language-based reasoning isn’t structured to handle such rapid and exact control loops, sometimes leading to worse performance in terms of cumulative rewards.